Products You May Like
AI-generated music is already an innovative enough concept, but Riffusion takes it to another level with a clever, weird approach that produces weird and compelling music using not audio but images of audio.
Sounds strange, is strange. But if it works, it works. And it does work! Kind of.
Diffusion is a machine learning technique for generating images that supercharged the AI world over the last year. DALL-E 2 and Stable Diffusion are the two most high-profile models that work by gradually replacing visual noise with what the AI thinks a prompt ought to look like.
The method has proved powerful in many contexts and is very susceptible to fine-tuning, where you give the mostly trained model a lot of a specific kind of content in order to have it specialize in producing more examples of that content. For instance, you could fine-tune it on watercolors or on photos of cars, and it would prove more capable in reproducing either of those things.
What Seth Forsgren and Hayk Martiros did for their hobby project Riffusion was fine-tune Stable Diffusion on spectrograms.
“Hayk and I play in a little band together, and we started the project simply because we love music and didn’t know if it would be even possible for Stable Diffusion to create a spectrogram image with enough fidelity to convert into audio,” Forsgren told TechCrunch. “At every step along the way we’ve been more and more impressed by what is possible, and one idea leads to the next.”
What are spectrograms, you ask? They’re visual representations of audio that show the amplitude of different frequencies over time. You have probably seen waveforms, which show volume over time and make audio look like a series of hills and valleys; imagine if instead of just total volume, it showed the volume of each frequency, from the low end to the high end.
Here’s part of one I made of a song (“Marconi’s Radio” by Secret Machines, if you’re wondering):
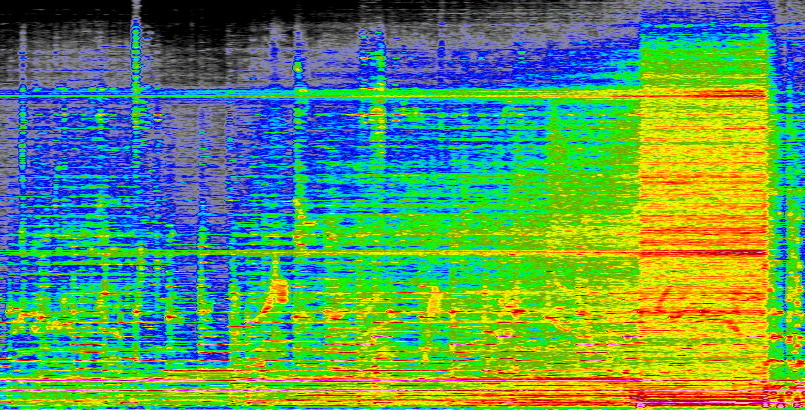
Image Credits: Devin Coldewey
You can see how it gets louder in all frequencies as the song builds, and you can even spot individual notes and instruments if you know what to look for. The process isn’t inherently perfect or lossless by any means, but it is an accurate, systematic representation of the sound. And you can convert it back to sound by doing the same process in reverse.
Forsgren and Martiros made spectrograms of a bunch of music and tagged the resulting images with the relevant terms, like “blues guitar,” “jazz piano,” “afrobeat,” stuff like that. Feeding the model this collection gave it a good idea of what certain sounds “look like” and how it might re-create or combine them.
Here’s what the diffusion process looks like if you sample it as it’s refining the image:

Image Credits: Seth Forsgren / Hayk Martiros
And indeed the model proved capable of producing spectrograms that, when converted to sound, are a pretty good match for prompts like “funky piano,” “jazzy saxophone,” and so on. Here’s an example:

Image Credits: Seth Forsgren / Hayk Martiros
But of course a square spectrogram (512 x 512 pixels, a standard Stable Diffusion resolution) represents only a short clip; a three-minute song would be a much, much wider rectangle. No one wants to listen to music five seconds at a time, but the limitations of the system they’d created mean they couldn’t just create a spectrogram 512 pixels tall and 10,000 wide.
After trying a few things, they took advantage of the fundamental structure of large models like Stable Diffusion, which have a great deal of “latent space.” This is sort of like the no-man’s-land between more well-defined nodes. Like if you had an area of the model representing cats, and another representing dogs, what’s “between” them is latent space that, if you just told the AI to draw, would be some kind of dogcat, or catdog, even though there’s no such thing.
Incidentally, latent space stuff gets a lot weirder than that:
No creepy nightmare worlds for the Riffusion project, though. Instead, they found that if you have two prompts, like “church bells” and “electronic beats,” you can kind of step from one to the other a bit at a time and it gradually and surprisingly naturally fades from one to the other, on the beat even:
It’s a strange, interesting sound, though obviously not particularly complex or high-fidelity; remember, they weren’t even sure that diffusion models could do this at all, so the facility with which this one turns bells into beats or typewriter taps into piano and bass is pretty remarkable.
Producing longer-form clips is possible but still theoretical:
“We haven’t really tried to create a classic 3-minute song with repeating choruses and verses,” Forsgren said. “I think it could be done with some clever tricks such as building a higher level model for song structure, and then using the lower level model for individual clips. Alternatively you could deeply train our model with much larger resolution images of full songs.”
Where does it go from here? Other groups are attempting to create AI-generated music in various ways, from using speech synthesis models to specially trained audio ones like Dance Diffusion.
Riffusion is more of a “wow, look at this” demo than any kind of grand plan to reinvent music, and Forsgren said he and Martiros were just happy to see people engaging with their work, having fun and iterating on it:
“There are many directions we could go from here, and we’re excited to keep learning along the way. It’s been fun to see other people already building their own ideas on top of our code this morning, too. One of the amazing things about the Stable Diffusion community is how fast people are to build on top of things in directions that the original authors can’t predict.”
You can test it out in a live demo at Riffusion.com, but you might have to wait a bit for your clip to render — this got a little more attention than the creators were expecting. The code is all available via the about page, so feel free to run your own as well, if you’ve got the chips for it.